
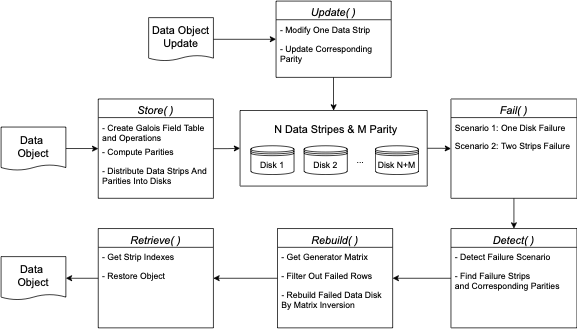
This is a project in NTU CE7490 Adcanced Topics in Distributed Systems. I have implemented the RAID-6 Based Distributed Storage System in Python. The project report is here.
In computer storage, the standard RAID levels comprise a basic set of RAID (“redundant array of independent disks” or “redundant array of inexpensive disks”) configurations that employ the techniques of striping, mirroring, or parity to create large reliable data stores from multiple general-purpose computer hard disk drives (HDDs).
RAID Family and RAID-6
RAID-0 distributes data chunks uniformly across N disks, which is called striping. RAID-1 mirrors data over $N$ disks, which utilizes 1/N space but can tolerate failure of up to N-1 disks. By combining RAID-1 and RAID-0, RAID-10 replicates each data strip once and thus reduces the useful storage by half. RAID-10 can tolerate 2 disk failures at maximum when these failed disks store different data. RAID-4 improves space utilization by storing data stripes in N-1 disks and parity in the N th disk. Parity is a calculated value from data strips, which is used to restore data from the other disks if one of the drives fails. However, due to the fact that every data restoration requires the data from the parity disk, the parity disk becomes an I/O bottleneck. To tackle this issue, RAID-5 distributes the parity over disks so that different disks may be used for restoring data rather than only the parity disk.
While the storage efficiency is improved, the single parity systems are fragile, especially when more than one failure occurs simultaneously. Besides, it may require a long rebuild time when the disk capacity is large. RAID-6 has been proposed to tolerate a second failed disk by distributing two parities over disks. There are various methods to implement RAID-6, including classic erasure coding techniques like Reed-Solomon (RS) coding and more specialized codes such as EVENODD and RDP. The relatively recent erasure code, Mojette, showed significant performance improvements at a price of slight storage overhead.

Application Example
In RS (10, 4) code, which is used in Facebook for their HDFS, 10 MB of user data is divided into ten 1MB blocks. Then, four additional 1 MB parity blocks are created to provide redundancy. This can tolerate up to 4 concurrent failures. The storage overhead here is 14/10 = 1.4X.
In the case of a fully replicated system, the 10 MB of user data will have to be replicated 4 times to tolerate up to 4 concurrent failures. The storage overhead in that case will be 50/10 = 5X.
This gives an idea of the lower storage overhead of erasure-coded storage compared to full replication and thus the attraction in today’s storage systems.