This is the project of NTU CE7455: Deep Learning For Natural Language Processing by Prof. Luu Anh Tuan. In this project, we aim to understand the effectiveness of text data augmentation using ChatGPT generated samples. I finetuned the pretrained DistilBERT model with IMDB review datasets and prompt-guided generated datasets for the sentiment classification task, which is to tell if the movie review is positive or negative. The code is in this notebook.
Introduction
The task of sentiment analysis, which identifies the emotion expressed in a text, is a crucial part of natural language processing. Despite the advances in deep learning for NLP, the requirement of a large amount of annotated data remains a challenge in applying deep learning models to sentiment analysis. One approach to tackle this challenge is data augmentation, where new training samples are artificially generated. Existing text data aug- mentation methods suffer from inconsistent semantics and poor diversity. AugGPT proposed a way to perform data augmentation using ChatGPT, a conversational AI model with strong generation capability. However, the diversity of the augmented data set is still limited by the training dataset. In this project, a fundamentally different approach is proposed to leverage ChatGPT for text data augmentation by generating diverse augment data from scratch using a set of carefully designed prompts. The effectiveness of this approach is evaluated by training sentiment analysis models with the augmented data and comparing their performance.
Related Work
Data Augmentation Approaches in Natural Language Processing: A Survey
The survey categories the data augmentation in NLP by paraphrasing (synonym, semantic embedding, translation, generation), noising (swapping, deletion, insertion, substation), and sampling-based methods (rules, pretrained, self-training, mixup).
Is GPT-3 a Good Data Annotator?
GPT-3 is used to label data that could be used to train machine learning models. GPT-3 performs best on text classification tasks when directly tagging test data in large scale. Prompt-guided or dictionary-assisted training data generation may be more effective and cost-efficient for complex tasks like name entity recognition.
AugGPT: Leveraging ChatGPT for Text Data Augmentation
Current text data augmentation methods either can’t ensure the correct labeling of the generated data or can’t ensure sufficient diversity in the generated data. AugGPT rephrases each sentence in the training samples into multiple conceptually similar but semantically different samples. Experiment on few-shot learning text classification tasks.
Carefull Designed Prompts
70 Prompts for Positive sentiments
- Write a 200 to 300 words long movie review about an action movie, where the author criticizes something but is positive about the movie overall.
- Write 10 unique, positive sentiment movie reviews that range from 10 to 300 words in length.
- Write 5 positive movie reviews about films that did not do well in the box office.
- Write 5 lengthy movie reviews about award-winning films.
- Write 7 movie reviews about adult-animation films.
- Write 5 positive movie reviews about movies that everyone hates except for the user.
- Write 5 positive movie reviews about weird films.
55 Prompts for Negative sentiments
- Write 3 movie reviews of at least 200 words criticizing an award-winning movie.
- Write 7 sarcastic movie reviews.
- Write a bad movie review from a stereotypical male perspective.
- Write a bad movie review from a stereotypical female perspective.
- Write 7 movie reviews from the perspective of a younger viewer who hated the film.
- Write 7 movie reviews from the perspective of an older viewer who hated the film.
- Write 2 bad reviews of 150-200 words about popular movies.
- Write bad movie reviews that compare it to another movie.
- Write 5 bad movie reviews from the perspective of a professional critic.
- Write bad movie reviews that make fun of the film.
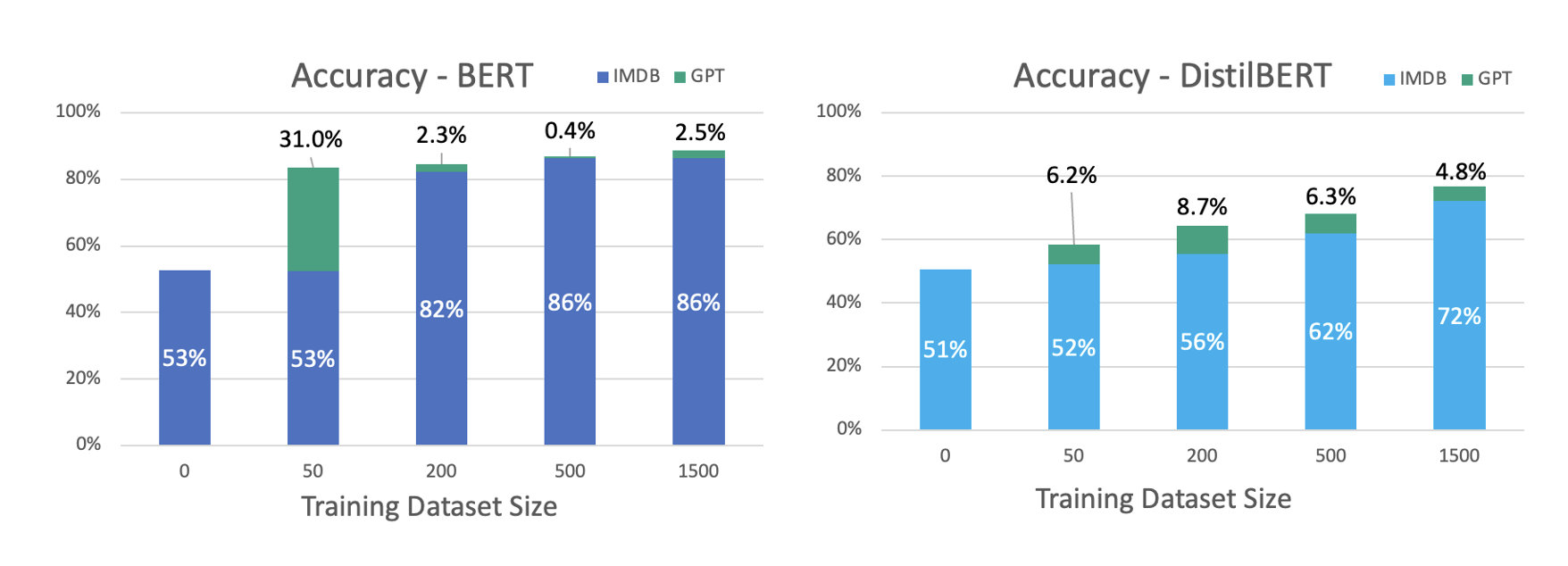
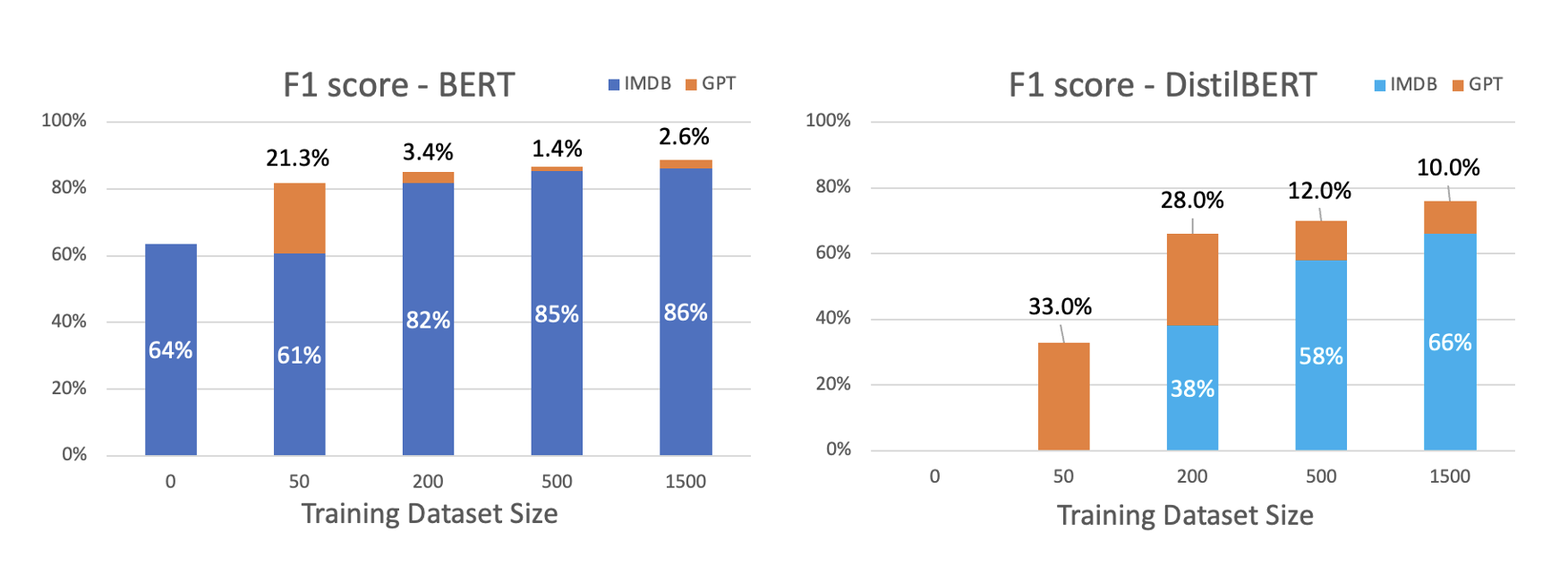
In total, 1500 ChatGPT-generated movie reviews.
Experiment Results