
This is the assignment of NTU CE7455: Deep Learning For Natural Language Processing by Prof. Luu Anh Tuan. In this assignment, I have implemented and analyzed seq2seq models for machine translation. The full report is here.
The data for this project is a set of many thousands of English to French translation pairs. Tab-delimited Bilingual Sentence Pairs are selected sentence pairs from the Tatoeba Project (http://www.manythings.org/anki/).
!wget http://www.manythings.org/anki/fra-eng.zip
!unzip -o fra-eng.zip
!mkdir data
!mv fra.txt data/eng-fra.txt
Data Preparation
Read text file and split into lines, split lines into pairs
To read the data file we will split the file into lines, and then split lines into pairs. The files are all English → Other Language, so if we want to translate from Other Language → English I added the reverse flag to reverse the pairs.
# Turn a Unicode string to plain ASCII
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')[:2]] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
Normalize text, filter by length and content
Since there are a lot of example sentences and we want to train something quickly, we’ll trim the data set to only relatively short and simple sentences. Here the maximum length is 10 words (that includes ending punctuation) and we’re filtering to sentences that translate to the form “I am” or “He is” etc. (accounting for apostrophes replaced earlier).
MAX_LENGTH = 15
eng_prefixes = (
"i am", "i m",
"he is", "he s",
"she is", "she s",
"you are", "you re",
"we are", "we re",
"they are", "they re"
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
Make word lists from sentences in pairs
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
Seq2Seq Model
A Sequence to Sequence network, or seq2seq network, or Encoder Decoder network, is a model consisting of two RNNs called the encoder and decoder. The encoder reads an input sequence and outputs a single vector, and the decoder reads that vector to produce an output sequence. The seq2seq model frees us from sequence length and order, which makes it ideal for translation between two languages.
Consider the sentence “Je ne suis pas le chat noir” → “I am not the black cat”. Most of the words in the input sentence have a direct translation in the output sentence, but are in slightly different orders, e.g. “chat noir” and “black cat”. Because of the “ne/pas” construction there is also one more word in the input sentence. It would be difficult to produce a correct translation directly from the sequence of input words.
With a seq2seq model the encoder creates a single vector which, in the ideal case, encodes the “meaning” of the input sequence into a single vector — a single point in some N dimensional space of sentences.
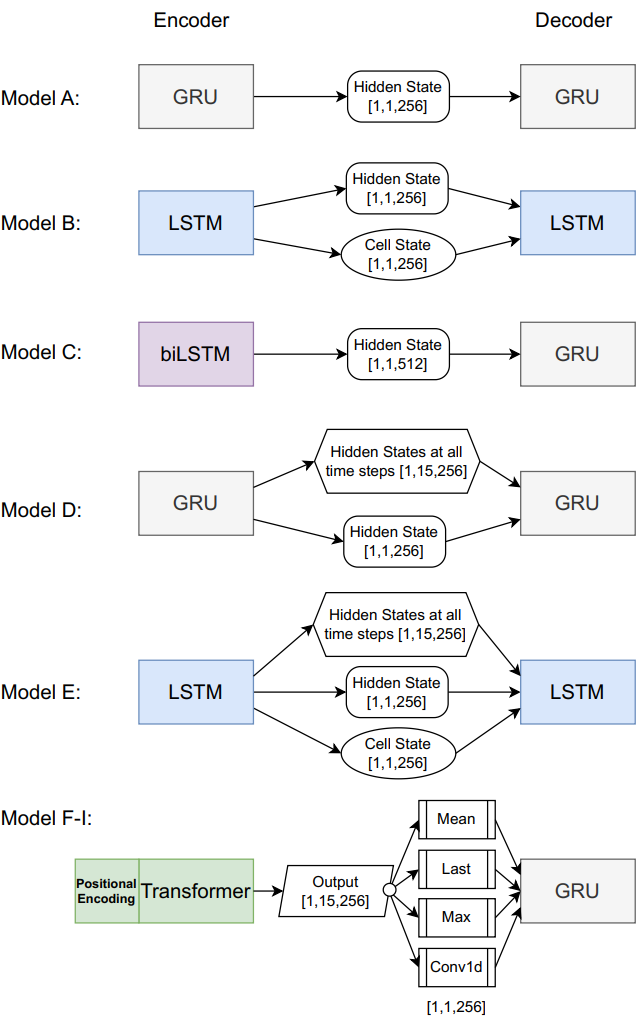
Encoder
A GRU encoder is showed as below.
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, num_layers=1)
def forward(self, _input, hidden):
embedded = self.embedding(_input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
A more complex Transformer based encoder is implemented as below.
class PositionalEncoding(nn.Module):
def __init__(self, dim_model, dropout_p, max_len):
super().__init__()
# Modified version from: https://pytorch.org/tutorials/beginner/transformer_tutorial.html
# max_len determines how far the position can have an effect on a token (window)
# Info
self.dropout = nn.Dropout(dropout_p)
# Encoding - From formula
pos_encoding = torch.zeros(max_len, dim_model)
positions_list = torch.arange(0, max_len, dtype=torch.float).view(-1, 1) # 0, 1, 2, 3, 4, 5
division_term = torch.exp(torch.arange(0, dim_model, 2).float() * (-math.log(10000.0)) / dim_model) # 1000^(2i/dim_model)
# PE(pos, 2i) = sin(pos/1000^(2i/dim_model))
pos_encoding[:, 0::2] = torch.sin(positions_list * division_term)
# PE(pos, 2i + 1) = cos(pos/1000^(2i/dim_model))
pos_encoding[:, 1::2] = torch.cos(positions_list * division_term)
# Saving buffer (same as parameter without gradients needed)
pos_encoding = pos_encoding.unsqueeze(0).transpose(0, 1)
self.register_buffer("pos_encoding",pos_encoding)
def forward(self, token_embedding: torch.tensor) -> torch.tensor:
# Residual connection + pos encoding
# print("token_embedding: ", token_embedding.shape)
pos = torch.permute(self.pos_encoding, (1,0,2))
# print("pos: ", pos.shape)
return self.dropout(token_embedding + pos)
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.dim_model = self.hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.positional_encoder = PositionalEncoding(
dim_model=self.hidden_size, dropout_p=0.1, max_len=MAX_LENGTH
)
self.trans = nn.TransformerEncoderLayer(
d_model=hidden_size,
nhead=4,
dim_feedforward=2048)
def forward(self, _input):
embedded = self.embedding(torch.transpose(_input,0,1)) * math.sqrt(self.dim_model)
# print("embedded: [1, 15, 256] - ", embedded.shape)
output = self.positional_encoder(embedded)
# print("trans output: [1, 15, 256] - ", output.shape)
output = self.trans(output)
# print("trans output: [1, 15, 256] - ", output.shape)
return output
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
Decoder
A typical GRU decoder receives output from the encoder as the initial hidden state, which is also called the context vector.
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, num_layers=1)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# Your code here #
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
Attention mechanism in introduced between the encoder and decoder to allow the model focus on certain key words in the input. My implementation is as below.
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.lstm = nn.LSTM(2*hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, _input, hidden, cell, encoder_hiddens):
# print("hidden: [1, 1, 256] - ", hidden.shape)
# print("encoder_hiddens: [15, 256] - ", encoder_hiddens.shape)
output = self.embedding(_input).view(1, 1, -1)
output = F.relu(output)
# print("output: [1, 1, 256] - ", output.shape)
# calculate the attention by dot product
att_score = torch.matmul(encoder_hiddens, torch.transpose(hidden[0],0,1))
# print("att_score: [15, 1] - ", att_score.shape)
# compute attention distribution
alpha = F.softmax(att_score, dim=0)
# print("alpha: [15, 1] - ", alpha.shape)
weighted = encoder_hiddens*alpha
# print("weighted: [15, 256] -", weighted.shape)
weighted = torch.sum(weighted,dim=0)
# print("weighted sum: [256] -", weighted.shape)
weighted = weighted[None, None, :]
# print("weighted sum: [1, 1, 256] - ", weighted.shape)
# attention output is concatenated with the token embeddings
output = torch.concat([output, weighted], dim=2)
output, (hidden, cell) = self.lstm(output, (hidden, cell))
output = self.softmax(self.out(output[0]))
return output, hidden, cell
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
Model Training
To train, for each pair we will need an input tensor (indexes of the words in the input sentence) and target tensor (indexes of the words in the target sentence). While creating these vectors we will append the EOS token to both sequences.
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
Training process is defined as below.
teacher_forcing_ratio = 0.5
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_cell = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
encoder_hiddens = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden, encoder_cell = encoder(
input_tensor[ei], encoder_hidden, encoder_cell)
encoder_outputs[ei] = encoder_output[0, 0]
encoder_hiddens[ei] = encoder_hidden[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
decoder_cell = encoder_cell
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_cell = decoder(
decoder_input, decoder_hidden, decoder_cell, encoder_hiddens)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_cell = decoder(
decoder_input, decoder_hidden, decoder_cell, encoder_hiddens)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
The whole training process:
- Start a timer
- Initialize optimizers and criterion
- Create set of training pairs
- Start empty losses array for plotting
def trainIters(encoder, decoder, epochs, print_every=1000, plot_every=100, learning_rate=0.01):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
criterion = nn.NLLLoss()
iter = 1
n_iters = len(train_pairs) * epochs
for epoch in range(epochs):
print("Epoch: %d/%d" % (epoch, epochs))
for training_pair in train_pairs:
training_pair = tensorsFromPair(training_pair)
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
iter +=1
Model Evaluation
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a family of evaluation metrics used to measure the quality of summaries produced by automatic summarization systems. ROUGE scores are based on the comparison of n-gram overlap between the generated summary and a set of reference summaries. ROUGE scores are typically reported as F-scores, which are harmonic means of precision and recall.
{kind=link}
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_cell = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
encoder_hiddens = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden, encoder_cell = encoder(input_tensor[ei],
encoder_hidden, encoder_cell)
encoder_outputs[ei] += encoder_output[0, 0]
encoder_hiddens[ei] = encoder_hidden[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device) # SOS
decoder_hidden = encoder_hidden
decoder_cell = encoder_cell
decoded_words = []
for di in range(max_length):
decoder_output, decoder_hidden, decoder_cell = decoder(
decoder_input, decoder_hidden, decoder_cell, encoder_hiddens)
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words
We can evaluate random sentences from the training set and print out the input, target, and output to make some subjective quality judgements:
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')
import numpy as np
from torchmetrics.text.rouge import ROUGEScore
rouge = ROUGEScore()
def test(encoder, decoder, testing_pairs):
_input = []
gt = []
predict = []
metric_score = {
"rouge1_fmeasure":[],
"rouge1_precision":[],
"rouge1_recall":[],
"rouge2_fmeasure":[],
"rouge2_precision":[],
"rouge2_recall":[]
}
for pair in testing_pairs:
output_words = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
_input.append(pair[0])
gt.append(pair[1])
predict.append(output_sentence)
metric_score["rouge1_fmeasure"].append(rouge(output_sentence, pair[1])['rouge1_fmeasure'])
metric_score["rouge1_precision"].append(rouge(output_sentence, pair[1])['rouge1_precision'])
metric_score["rouge1_recall"].append(rouge(output_sentence, pair[1])['rouge1_recall'])
metric_score["rouge2_fmeasure"].append(rouge(output_sentence, pair[1])['rouge2_fmeasure'])
metric_score["rouge2_precision"].append(rouge(output_sentence, pair[1])['rouge2_precision'])
metric_score["rouge2_recall"].append(rouge(output_sentence, pair[1])['rouge2_recall'])
metric_score["rouge1_fmeasure"] = np.array(metric_score["rouge1_fmeasure"]).mean()
metric_score["rouge1_precision"] = np.array(metric_score["rouge1_precision"]).mean()
metric_score["rouge1_recall"] = np.array(metric_score["rouge1_recall"]).mean()
metric_score["rouge2_fmeasure"] = np.array(metric_score["rouge2_fmeasure"]).mean()
metric_score["rouge2_precision"] = np.array(metric_score["rouge2_precision"]).mean()
metric_score["rouge2_recall"] = np.array(metric_score["rouge2_recall"]).mean()
print("=== Evaluation score - Rouge score ===")
print("Rouge1 fmeasure:\t",metric_score["rouge1_fmeasure"])
print("Rouge1 precision:\t",metric_score["rouge1_precision"])
print("Rouge1 recall: \t",metric_score["rouge1_recall"])
print("Rouge2 fmeasure:\t",metric_score["rouge2_fmeasure"])
print("Rouge2 precision:\t",metric_score["rouge2_precision"])
print("Rouge2 recall: \t",metric_score["rouge2_recall"])
print("=====================================")
return _input,gt,predict,metric_score
hidden_size = 256
encoder = Encoder(input_lang.n_words, hidden_size).to(device)
decoder = Decoder(hidden_size, output_lang.n_words).to(device)
trainIters(encoder, decoder, 2, print_every=5000)
evaluateRandomly(encoder, decoder)
> il est le president du comite .
= he s the chairman of the committee .
< he is the the of . . <EOS>
> j ai fait un bonhomme de neige .
= i made a snowman .
< i m a a of . <EOS>
> je suis conscient de tout cela .
= i m aware of all that .
< i m glad of that . <EOS>
> ce n est pas ma petite amie . c est ma s ur .
= she s not my girlfriend . she s my sister .
< she is my my my . . my is . <EOS>
> je ne suis pas d humeur .
= i m not in the mood .
< i m not in the . . <EOS>
> vous avez un mois de loyer en retard .
= you re a month behind in your rent .
< you re in a late . . <EOS>
> nous nous dirigeons vers le nord .
...
> tu te comportes tres bizarrement .
= you re acting very strangely .
< you re very very . . <EOS>
=== Evaluation score - Rouge score ===
Rouge1 fmeasure: 0.54421055
Rouge1 precision: 0.5288596
Rouge1 recall: 0.5705757
Rouge2 fmeasure: 0.34525457
Rouge2 precision: 0.33032423
Rouge2 recall: 0.37114966
=====================================